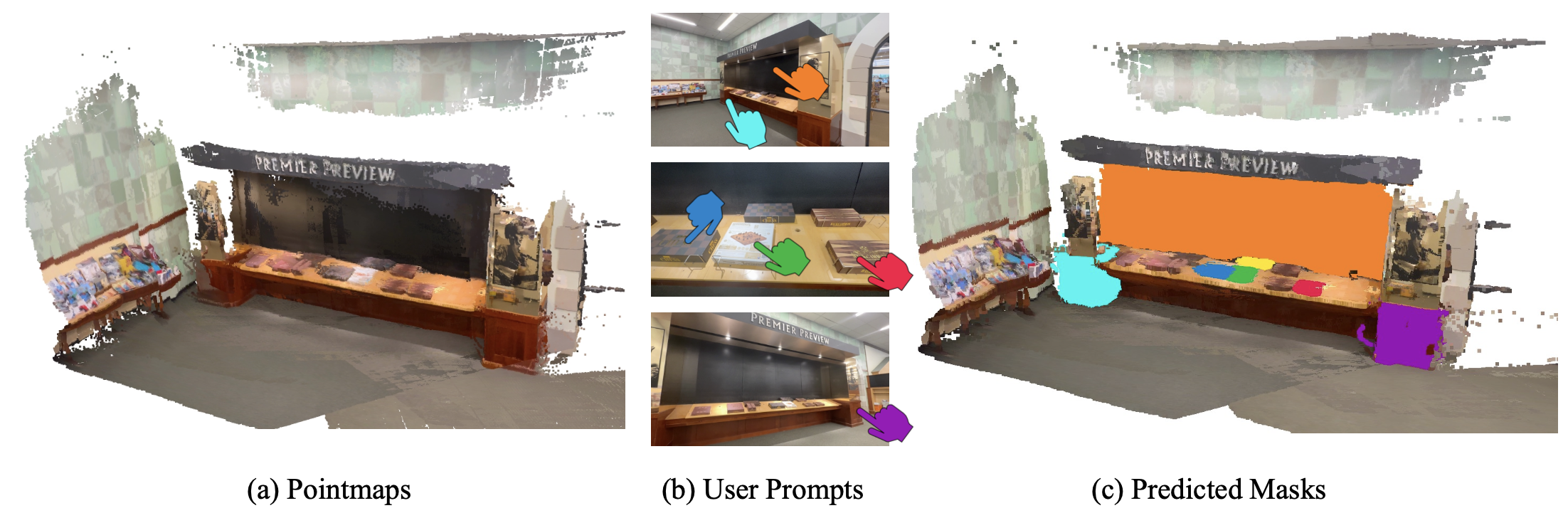
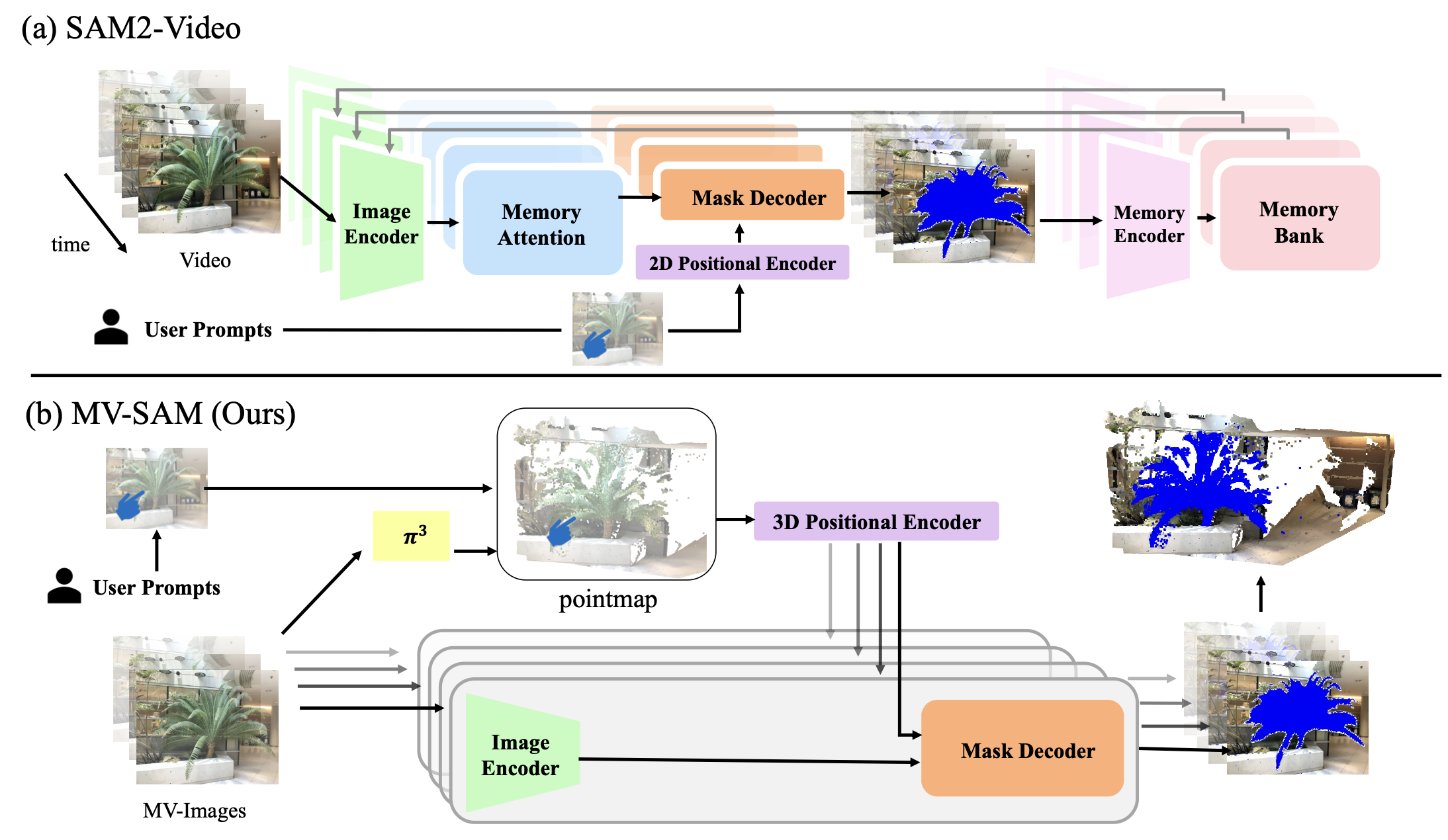
Promptable segmentation has emerged as a powerful paradigm in computer vision, enabling users to guide models in parsing complex scenes with prompts such as clicks, boxes, or textual cues. Recent advances, exemplified by the Segment Anything Model (SAM), have extended this paradigm to videos and multi-view images. However, the lack of 3D awareness often leads to inconsistent results, necessitating costly per-scene optimization to enforce 3D consistency. In this work, we introduce MV-SAM, a framework for multi-view segmentation that achieves 3D consistency using pointmaps--3D points reconstructed from unposed images by recent visual geometry models. Leveraging the pixel–point one-to-one correspondence of pointmaps, MV-SAM lifts images and prompts into 3D space, eliminating the need for explicit 3D networks or annotated 3D data. Specifically, MV-SAM extends SAM by lifting image embeddings from its pretrained encoder into 3D point embeddings, which are decoded by a transformer using cross-attention with 3D prompt embeddings. This design aligns 2D interactions with 3D geometry, enabling the model to implicitly learn consistent masks across views through 3D positional embeddings. Trained on the SA-1B dataset, our method generalizes well across domains, outperforming SAM2-Video and achieving comparable performance with per-scene optimization baselines on NVOS, SPIn-NeRF, ScanNet++, uCo3D, and DL3DV benchmarks. Code will be released.